Сборка тестера нагрузки PostgreSQL
Ссылка на оригинал - https://blog.lawrencejones.dev/building-a-postgresql-load-tester/, автор публикации - Lawrence Jones
Некоторые из моих недавних работ в GoCardless обнаружили необходимость в тестировании кластера Postgres. В попытке симулировать реалистичную рабочую нагрузку я написал инструмент, который воспроизводит захваченную активность Postgres на работающем сервере, предоставляя возможность предсказать, как запросы могут ухудшаться при изменении конфигурации.
Этот пост посвящен реализации pgreplay-go, инструмента для реалистичной симуляции захваченного трафика Postgres. Я объясню, почему существующие инструменты не подходят, и объясню некоторые проблемы в реализации, сосредоточив внимание на том, что я узнал лично из процесса.
Предшествующий уровень техники
Столкнувшись с технической проблемой, часто лучше использовать существующий инструмент, чем самостоятельно писать его. Раньше сравнивая кластеры Postgres, я уже был знаком с инструментом pgreplay, который, как я думал, мог бы справиться с этой задачей.
Моя стратегия бенчмаркинга с pgreplay довольно проста: сначала запишите журналы с вашего производственного кластера, которые содержат все выполненные запросы, а затем передайте их в pgreplay, который будет воспроизводить эти запросы для нового кластера. Журналы постобработки из нового кластера покажут, как машины работают под рабочей нагрузкой, и помогут определить, не приведут ли изменения к снижению производительности.
Этот процесс работал хорошо раньше, но прервался, как только я применил его к этой миграции. Наблюдая за Postgres во время воспроизведения, всплески активности сопровождались периодами тишины:
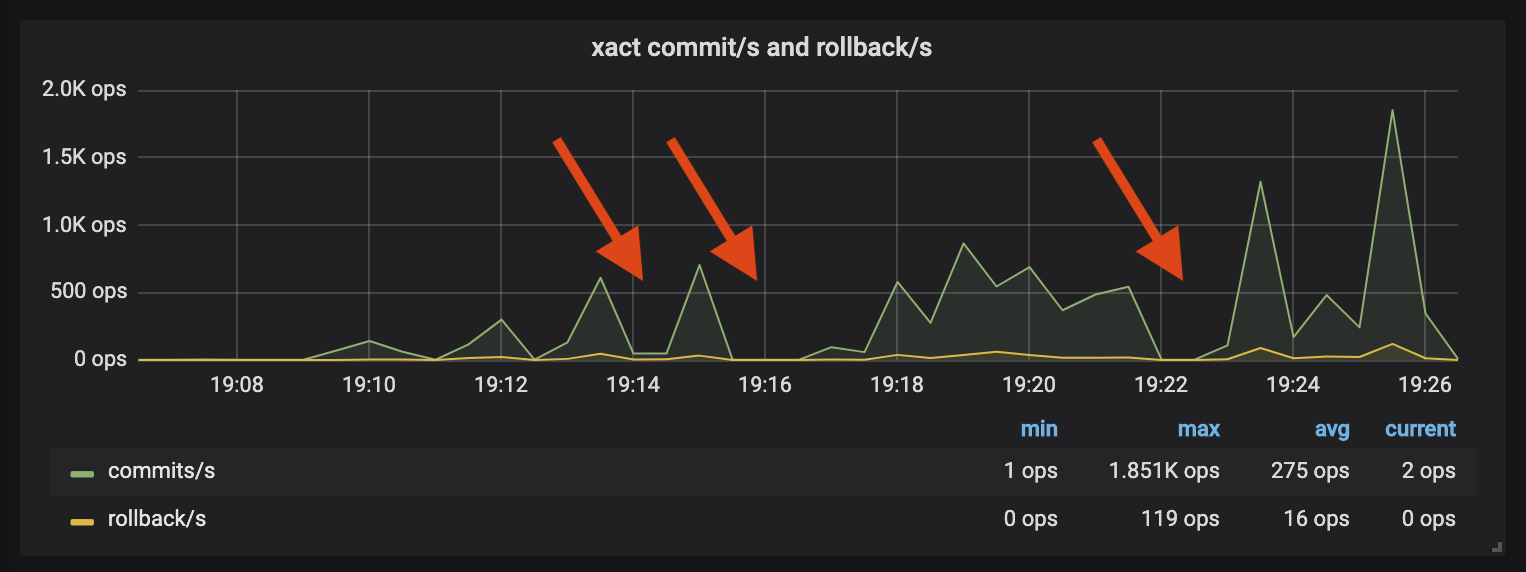
Новый кластер был достаточно разным, так что несколько запросов теперь выполнялись намного медленнее, чем при первоначальном захвате журнала. pgreplay обеспечит выполнение запросов в их первоначальном порядке - любые запросы, которые будут выполняться дольше, будут блокировать последующие запросы. На графике показано, как несколько сильно ухудшенных запросов вызвали остановку pgreplay, что привело к периодам бездействия.
Выполнение тестов может занять несколько часов, а остановка воспроизведения для проблемных запросов увеличивает время и без того медленного процесса. Отсутствие активности также влияет на реалистичность ваших тестов - пользователи не реагируют на загруженную систему, формируя очередь и вежливо ожидая завершения первого запроса!
Реализация
Так что, если это не сработает, что может? Мне показалось, что лучшей стратегией воспроизведения будет такая, которая будет моделировать каждое соединение в отдельности, когда длительные запросы будут влиять только на их собственное соединение. Это позволяет нам измерить влияние нашего ухудшенного запроса на другой трафик, продолжая оставшуюся часть нашего воспроизведения.
Так же, как и в оригинальном pgreplay, инструмент, который достигает этого, будет иметь всего несколько компонентов: анализатор журналов Postgres, который создает работу для воспроизведения, стример, который может ускорить выполнение в соответствии с исходными журналами, и базу данных, которая может моделировать текущие соединения , Инструмент должен быть быстрым (возможно, скомпилированным языком?) И использовать среду выполнения с дешевым параллелизмом для моделирования каждого соединения.
Нам потребовались результаты тестов в течение недели, то есть было три (оставалось два дня для проведения тестов) дней, чтобы построить что-то, отвечающее этим целям. Это было бы близко, но три дня считалось возможным создать этот инструмент воспроизведения Златовласка, особенно с языком, с которым я уже был знаком.
В порыве оптимистичной наивности я решил, что стоит попробовать.
Разбор логов: как тяжело это может быть?
По необходимости мы начинаем с анализа логов Postgres. Сначала я думал, что это будет легко и не могло быть более неправильно!
Многострочный токенинг
При разборе журналов вы обычно разбиваете файл на новые строки, чтобы найти каждую запись, но формат Postgres errlog работает не так. Поскольку большинство записей журнала содержат символы новой строки, формат errlog позволяет использовать символы новой строки, добавляя префиксы в начале к символу табуляции ( \t).
2019-02-25 15:08:27.239 GMT|alice|pgreplay_test|5c7404eb.d6bd|LOG: statement: insert into logs (author, message)
values ('alice', 'says hello');
Анализ этого типа журнала более сложен, чем разбиение на новые строки. Вместо того чтобы сканировать файл в поисках символа ( \n), вы сканируете, пока не увидите, что за вашим символом не следует дополнительный маркер ( \nза ним не следует \t). Это требует, чтобы сканер смотрел вперед, где текущий токен завершится, усложняя логику, когда нужно разделить.
Учитывая, что это был небольшой, простой проект, я стремился избегать генераторов парсера с большим весом, которые потребовали бы дополнительного этапа сборки. Вместо этого я потянулся к стандартной библиотеке для токенизации моих строк журнала - в конце концов, Go имеет интерфейс, названный Scanner именно для этой цели.
Несколько часов спустя и некоторое значительное разочарование, у меня была функция сплиттера, полная подверженной ошибкам мутации и отчетливого чувства, strtokкоторое было бы менее болезненным. Это было то, что я не учел при выборе Go для реализации, но поддержка stdlib для работы со строками действительно слабая по сравнению с тем, к чему я привык. Меня застало врасплох, что Го так плохо подходит для этой задачи.
Несмотря на это, теперь у меня было что-то, что могло анализировать отдельные записи в журнале, и я был уверен, что худшее уже позади. Следующая проблема, пожалуйста!
Разбор элементов журнала (Простой против Расширенного)
Черт возьми, это не сработало так, как я думал.
Клиенты Postgres могут использовать один из двух протоколов запросов для подачи команд на сервер. Первый - это простой протокол, в котором клиент отправляет текстовую строку, содержащую SQL, со всеми параметрами, уже интерполированными в строку запроса. Простые запросы будут регистрироваться так:
[1] LOG: statement: select now();
Это легко - мы анализируем запрос из этой строки и выполняем его на сервере. Это расширенный протокол, который становится сложным.
Протокол расширенного запроса обеспечивает безопасную обработку параметров запроса, отделяя запрос SQL от введения значений параметров. Сначала клиент предоставляет запрос с заполнителями параметров, затем следует значения для этих параметров. Выполнение select $1, $2с параметрами aliceи bobприведет к следующим журналам:
[1] LOG: duration: 0.042 ms parse <unnamed>: select $1, $2; [2] LOG: duration: 0.045 ms bind <unnamed>: select $1, $2; [3] DETAIL: parameters: $1 = 'alice', $2 = 'bob' [4] LOG: execute <unnamed>: select $1, $2; [5] DETAIL: parameters: $1 = 'alice', $2 = 'bob' [6] LOG: duration: 0.042 ms
Строки журналов 1, 2 и 3 представляют начальную подготовку этого запроса, где Postgres создает подготовленный оператор без указания имени и связывает два наших параметра. Планирование запроса происходит на этапе связывания, но в строке 4 мы знаем, что наш запрос начал выполнение.
Не обращая внимания на все, кроме 4 и 5, как бы мы проанализировали эти строки журнала в исполняемые инструкции? Мы можем видеть, что за DETAILзаписью выполнения подготовленного оператора сразу же следует запись в журнале, описывающая значения параметров, но нам необходимо объединить их вместе, прежде чем мы узнаем, какой запрос выполнить.
Теперь стоит обсудить интерфейсы, которые мы будем использовать для анализа этих логов. Основной интерфейс синтаксического анализа ParserFunc, который принимает файл erglog Postgres и создает канал воспроизведения Item, где Itemобозначает активную запись в журнале, которая может быть сделана Handleбазой данных.
type ParserFunc func(io.Reader) (
items chan Item, errs chan error, done chan error
)
var _ Item = &Connect{}
var _ Item = &Disconnect{}
var _ Item = &Statement{}
var _ Item = &BoundExecute{}
type Item interface {
GetTimestamp() time.Time
GetSessionID() SessionID
GetUser() string
GetDatabase() string
Handle(*pgx.Conn) error
}
Мы ожидаем, что наш парсер будет работать с очень большими (> 100 ГБ) файлами журналов и лениво выдавать проанализированные файлы, как только мы их проанализируем. Из четырех категорий, которые Item мы можем проанализировать, BoundExecute представляет собой комбинацию подготовленного оператора и его параметров запроса.
Поскольку подготовленные операторы с параметрами запроса входят в две строки журнала, наш процесс синтаксического анализа может успешно проанализировать строку журнала (например,Execute запись) без ее завершения, поскольку в ней отсутствуют параметры. Моделирование этой концепции требовало другого типа для представления Execute записи:
type Execute struct {
Query string `json:"query"`
}
func (e Execute) Bind(parameters []interface{}) BoundExecute {
return BoundExecute{e, parameters}
}
В отличие от всех других типов, интерфейс Execute не удовлетворяет, так Item как в нем отсутствует Handle метод, поэтому мы никогда не сможем отправить его по нашему каналу результатов (chan Item). Когда мы анализируем наши элементы, мы отслеживаем последнюю распознанную Execute строку журнала по каждому действующему соединению SessionID и передаем это сопоставление, чтобы ParseItem оно могло сопоставить последующие DETAIL записи с несвязанными выполнениями:
func ParseItem(logline string, unbounds map[SessionID]*Execute) (Item, error) {
...
// LOG: execute <unnamed>: select pg_sleep($1)
// execute items are parsed incompletely and stored in our unbounds
// map for later matching against DETAILSs.
if strings.HasPrefix(msg, LogExtendedProtocolExecute) {
unbounds[details.SessionID] = &Execute{details, parseQuery(msg)}
return nil, nil // return nothing for now
}
// DETAIL: parameters: $1 = '1', $2 = NULL
// This log line should match a previously parsed execute that is
// unbound. We expect to return the bound item.
if strings.HasPrefix(msg, LogExtendedProtocolParameters) {
if unbound, ok := unbounds[details.SessionID]; ok {
// Remove the unbound from our cache and bind it
delete(unbounds, details.SessionID)
return unbound.Bind(ParseBindParameters(msg)), nil
}
}
}
Поддерживая несвязанный кеш как часть функции синтаксического анализа с сохранением состояния, мы можем поддерживать двухэтапный процесс объединения строк исполнения и детализации в один элемент воспроизведения. Представляя нашу Execute запись как тип без Handle метода, мы используем систему типов Go, чтобы обеспечить и сообщить о неполноте этой записи в журнале, помогая компилятору отлавливать всякий раз, когда эти элементы были неправильно отправлены в базу данных для воспроизведения.
Хотя это было сложно и намного сложнее, чем я ожидал, было приятно найти решение для синтаксического анализа, которое можно хорошо выразить в системе типов Go.
Ленивый поток
Теперь мы проанализировали наши логи, нам нужно воспроизвести элементы с очевидной скоростью, с которой они были первоначально выполнены. Мы можем изобразить наш тест в виде конвейера элементов воспроизведения, которые сначала анализируются, затем передаются в потоковом режиме и, наконец, используются базой данных:
parse(logs) -> stream(replayRate) -> replay(database)
В идеале этот инструмент воспроизведения будет настолько эффективным, что мы сможем запустить его из того же окна, что и целевой Postgres, не влияя на наш тест. Это требует от нас ограничения скорости синтаксического анализатора, чтобы он мог читать только столько журналов, сколько нам нужно в настоящее время для воспроизведения, что не позволяет нам разбирать наш диск при разборе ГБ журналов в начале каждого теста.
Необходимость лениво потреблять наши журналы - вот почему реализация синтаксического анализа возвращает chan Itemасинхронно принимаемые проанализированные элементы. Отправка сообщения по каналу Go блокирует вызывающую программу до тех пор, пока сообщение не будет использовано. Мы можем использовать это поведение, внедрив наш потоковый компонент в качестве потребителя нашего канала синтаксического анализа, извлекая элементы из анализатора только тогда, когда они должны быть использованы в соответствии с их исходным временем записи в журнале.
С удалением некоторых деталей реализация Stream выглядит так:
// Stream consumes items from the given channel and returns a channel
// that will receive those events at a simulated given rate.
func (s Streamer) Stream(items chan Item, rate float64) (out chan Item) {
go func() {
var first, start time.Time
var seenItem bool
for item := range items {
// Calculate the time elapsed since we started our stream, adjusted
// for our playback rate
elapsedSinceStart := time.Duration(rate) * time.Now().Sub(start)
// Time elapsed between the current and first item we processed
elapsedSinceFirst := item.GetTimestamp().Sub(first)
// If the amount of time from our first item to the current is
// greater than our current stream runtime, sleep for that period
// of time adjusted by our rate.
if diff := elapsedSinceFirst - elapsedSinceStart; diff > 0 {
time.Sleep(time.Duration(float64(diff) / rate))
}
// Now we've appropriately throttled, we can push the item
out <- item
}
}()
return
}
Измеряя временную метку каждого элемента относительно относительного прогресса нашего потока, мы можем отправить элемент только тогда, когда мы знаем, что он должен. Всякий раз, когда мы делаем паузу на элементе, который прибыл рано, мы прекращаем вытягивать из нашего входного канала, обеспечивая паузы разбора в восходящем потоке, пока мы не продолжим. То же самое касается нажатия на наш выходной канал, где мы будем останавливаться, пока наша нижестоящая база данных не примет сообщение.
Индивидуальные сеансы воспроизведения
Теперь мы находимся в нашем последнем компоненте, где мы воспроизводим наши удушенные элементы выполнения в целевой базе данных.
Как бы мы это ни строили, мы хотим избежать исходной проблемы, когда один ухудшенный запрос блокирует все воспроизведение. Выбранная стратегия состоит в том, чтобы моделировать каждую сессию индивидуально, снабжая предметы каждой отдельно. Ухудшенные запросы будут блокировать только элементы, которые следуют в том же сеансе, избегая пауз «остановка мира», которые мы видели с нашим первоначальным сравнительным тестированием.
Как и в случае со стримером, мы вытащим предметы из нашего лениво поставленного chan Item. Функция Consume выглядит примерно так:
func (d *Database) Consume(items chan Item) (chan error, chan error) {
var wg sync.WaitGroup
errs, done := make(chan error, 10), make(chan error)
go func() {
for item := range items {
var err error
conn, ok := d.conns[item.GetSessionID()]
// Connection did not exist, so create a new one
if !ok {
d.conns[item.GetSessionID()] = d.Connect(item)
wg.Add(1)
// Start our connection control loop, asynchronously
// processing items for its session
go func(conn *Conn) {
defer wg.Done()
conn.Start()
}(conn)
}
conn.In() <- item
}
// We've received every item, so close our channels
for _, conn := range d.conns {
conn.Close()
}
// Wait for every connection to terminate
wg.Wait()
close(errs)
close(done)
}()
return errs, done
}
Мы отображаем каждую сессию Postgres на свою собственную программу, где мы обрабатываем элементы по мере их поступления от нашего стримера. sync.WaitGroup используется для ожидания завершения всех наших соединений, прежде чем сообщить о том, что мы закончили.
Поскольку каждое соединение может потенциально получать тысячи элементов при выполнении ухудшенного запроса, нам нужны каналы, которые имеют «бесконечный» буфер. Go не имеет встроенной поддержки для этого, но библиотека eapache / channel предоставляет InfiniteChannel тип, который работает просто отлично.
Отладка
После нескольких дней совместной работы я наконец-то получил что-то, что (скрестив пальцы!) Могло бы достичь того, что мы искали. Я уже собрал логи, поэтому приступил к настройке нашего тестового компьютера.
Производительность анализатора (15 МБ / с -> 340 МБ / с)
Первые впечатления были великолепны: наблюдение за показателями машин Postgres показало постоянный уровень активности, свободный от поведения «старт-стоп», которое мы видели при использовании оригинального инструмента pgreplay. Все выглядело менее радужно при сравнении цифр с производством, где пиковые значения были в 4 раза выше, чем во время тестов.
Что-то не поспевало за нашим тестом. По догадкам, я изменил код pgreplay, чтобы не предпринимать никаких действий с проанализированными элементами, и попытался запустить воспроизведение, измеряя скорость чтения файла журнала. Неудивительно, что мы разбирали наши журналы гораздо медленнее, чем я надеялся…
$ pv --rate postgresql.log | pgreplay run --errlog-input /dev/stdin ts=2019-04-06T19:15:27.045501Z caller=level.go:63 event=metrics.listen address=127.0.0.1 port=9445 [15.5MiB/s]
Производственный экземпляр, который создавал журналы эталонных тестов, иногда обрабатывал журналы со скоростью 30 МБ / с. Если при синтаксическом анализе журналов мы достигли 15 МБ / с, наше воспроизведение не сможет полностью воспроизвести производственный трафик.
К счастью, Go имеет отличную поддержку для профилирования и компилятор, который может предоставить подсказки по оптимизации. Запуск go buildс -gcflags '-m'включит предупреждения анализа выхода, которые могут помочь выявить проблемы оптимизации.
$ go build -gcflags '-m' parse.go ./parse.go:249:16: func literal escapes to heap ./parse.go:248:29: &bufio.Scanner literal escapes to heap ./parse.go:247:20: leaking param: input to result ~r1 level=-1 ./parse.go:178:16: func literal escapes to heap ./parse.go:177:47: strings.NewReader(input) escapes to heap ./parse.go:177:47: &strings.Reader literal escapes to heap ...
Написание исполняемого кода для языков с автоматическим управлением памятью часто требует избегать выделения памяти. В идеальном мире все функциональные переменные будут размещены в стеке, так как переменные, выделенные в стеке, не требуют дополнительных затрат на сборку мусора, поскольку они автоматически освобождаются при возврате функции.
Моя первая попытка синтаксического анализа была отличным примером того, как не оптимизировать распределение памяти. Выбор одного из худших фрагментов:
func ParseBindParameters(input string) ([]interface{}, error) {
parameters := make([]interface{}, 0)
prefixMatcher := regexp.MustCompile(`^(, )?\$\d+ = `)
scanner := bufio.NewScanner(strings.NewReader(input))
scanner.Split(func(data []byte, atEOF bool) (int, []byte, error) {
...
}
...
}
В этом отрывке мы поставляемся анонимная функция, Split, которая имеет на спринклер parametersи prefixMatcher переменных во внешней области видимости функции. Поскольку анонимные функции могут пережить своего родителя, все переменные, на которые они ссылаются, исключаются для распределения в стеке, чтобы избежать их освобождения перед использованием. Анализ побега Go дал понять, что наши переменные были выделены кучей с помощью X escapes to the heap, и разумно предположить, что это существенно повлияет на производительность парсинга.
Я проходил каждое предупреждение, превращая анонимные функции в статические функции пакета и сокращая (где это возможно) мое использование объектов, выделенных в куче. Это и пара изменений для добавления буферов привели к увеличению скорости разбора в 16 раз до 346 МБ / с:
$ pv --rate postgresql.log | pgreplay run --errlog-input /dev/stdin ts=2019-04-06T19:58:18.536661Z caller=level.go:63 event=metrics.listen address=127.0.0.1 port=9445 [ 346MiB/s]
Тупики и сегфо
Теперь я был так близок к функциональному эталону, и то, что я видел по нашим показателям, давало мне реальную надежду. Мои тестовые тесты начались бы с того же объема активности, что и производство в нашем целевом кластере, до…
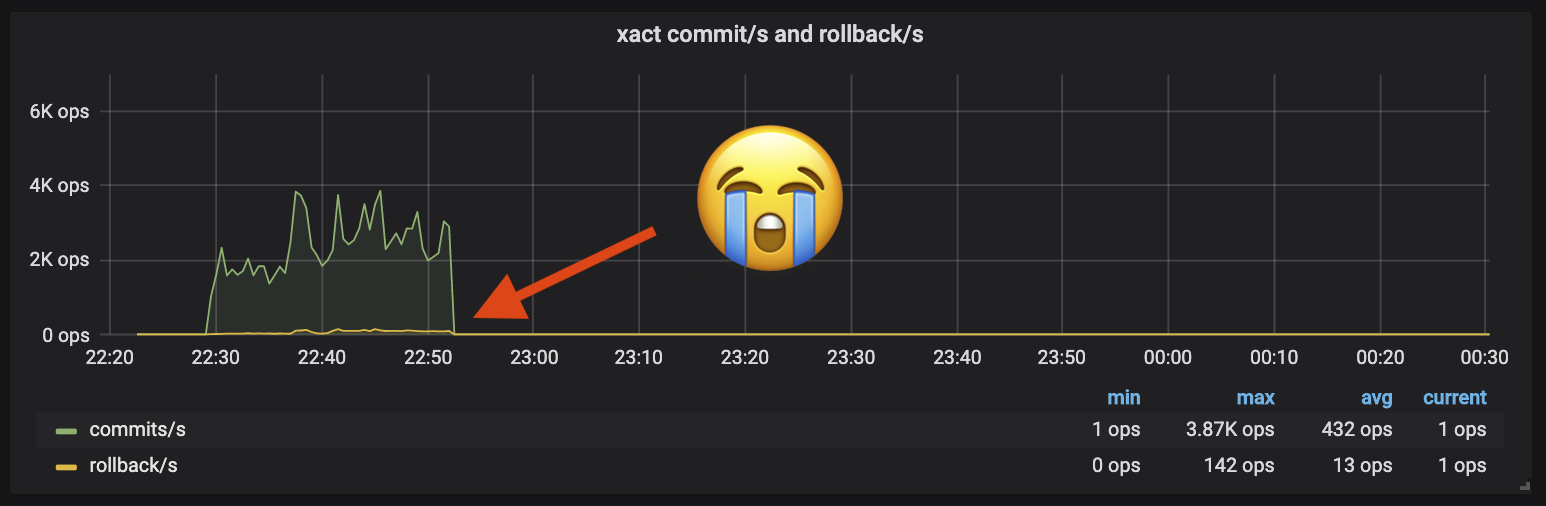
В то время как близко, умирание только 20 м в 3-часовой отметке не собирается сокращать это. Потеряв несколько часов на отладку взаимоблокировок и ошибок, стало ясно, что мне нужно больше видимости. Go известен многими вещами, но бесстрашный параллелизм не является одним из них - так много вещей может пойти не так, как угадывание, не уведя меня далеко без дополнительной информации.
Я пролистал каждый компонент конвейера и добавил простые метрики Prometheus, которые помогли мне понять, какая стадия глушит. Наряду с моими пользовательскими метриками появилась статистика времени выполнения Go, которая полезна для отслеживания активности рутин, помогая отлаживать тупиковые ситуации. Эта новая информация позволила мне отследить оставшиеся проблемы, пока я не смог успешно выполнить многочасовой тест.
Выводы
Пересматривая, почему я начал эту работу, pgreplay-go решает мои проблемы с pgreplay и позволяет мне уверенно тестировать новый кластер Postgres. Мало того, что он получил результаты, в которых нуждалась моя команда, путь от первоначального коммита до функционального инструмента произошел в течение пятидневного графика, который я установил с самого начала.
Помимо простого решения проблемы, мне нравилось ошибаться с каждым из моих предположений о том, насколько легко будет решить эту задачу. Это было глупо, когда ничего не получалось так, как я ожидал, и мне действительно нравилось отлаживать каждую проблему по мере ее появления.
Что касается обучения, теперь я знаю намного больше о протоколах и протоколах соединений Postgres. Это была также возможность попрактиковаться в программировании на Go и познакомиться с оптимизацией моего кода. Наконец, внедрение метрик Prometheus даже для такого небольшого проекта напомнило мне о том, насколько дешевой может быть наблюдаемая инвестиция за ту огромную ценность, которую вы получаете, когда ее настраиваете.
Полный исходный код и скомпилированные двоичные файлы для pgreplay-go можно найти здесь. Читатели могут с нетерпением ждать будущих публикаций GoCardless о результатах тестирования PostgreSQL!