Начало работы с io_uring с помощью Go
Ссылка на оригинал - https://developers.mattermost.com/blog/hands-on-iouring-go/, автор публикации - Agniva De Sarker
В Linux системные вызовы (syscalls) лежат в основе всего. Они являются основным интерфейсом, через который приложение взаимодействует с ядром. Поэтому очень важно, чтобы они были быстрыми. И особенно в мире после падения/расплава, это тем более важно.
Большая часть системных массивов имеет дело с вводом/выводом, потому что это то, что делает большинство приложений. Для сетевого ввода/вывода у нас есть семейство системных систем epoll, которые обеспечивают нам достаточно высокую производительность. Но в отделе ввода/вывода файловой системы чего-то не хватало. Некоторое время у нас была async_io, но кроме небольшого нишевого набора приложений, это не очень выгодно. Главная причина в том, что он работает только в том случае, если файл открыт флагом O_DIRECT. Это заставит ядро обойти любые кэши ОС и попытаться прочитать/записать с/на устройство напрямую. Не очень хороший способ ввода/вывода, когда мы пытаемся заставить все работать быстро. И в буферизованном режиме он будет вести себя синхронно.
Всё это медленно меняется, потому что теперь у нас есть совершенно новый интерфейс для выполнения ввода/вывода с ядром - io_uring. Вокруг него много шума. И это правильно, потому что это дает нам совершенно новую модель для взаимодействия с ядром. Давайте погрузимся в нее и попробуем понять, что это такое и как она решает проблему. А затем построим небольшое демо-приложение с Go, чтобы с ним поиграть.
Задний план
Давайте сделаем шаг назад и подумаем о том, как работают обычные системные вызовы. Мы делаем системный вызов, наше приложение на уровне пользователя вызывает ядро, оно создает копию данных в пространстве ядра. После того как ядро завершит выполнение, оно копирует результат обратно в буферы пространства пользователя. И тогда это возвращается. Все это время системный вызов остается заблокированным.
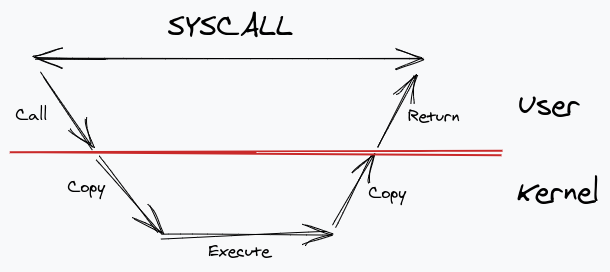
Сразу же мы можем увидеть множество узких мест - много копий и блокировок. Go решает эту проблему, создавая еще один слой между приложением и ядром - среду выполнения. Он использует виртуальную сущность (обычно называемую P ), которая содержит очередь подпрограмм для запуска, которая затем сопоставляется с потоками ОС.
Этот уровень косвенности позволяет ему делать некоторые интересные оптимизации. Всякий раз, когда мы делаем блокирующий системный вызов, среда выполнения узнает об этом, и он отсоединяет поток от P, выполняющего программу, и получает новый поток для выполнения других процедур. Это известно как передача. А когда возвращается системных вызовов, среда выполнения пытается повторно прикрепить его к P . Если он не может получить свободный P , он просто помещает goroutine в очередь для последующего выполнения и сохраняет поток в пуле. Вот как Go создает видимость «неблокирования», когда ваш код входит в системный вызов.
Это замечательно, но это все еще не решает главную проблему - то, что копии все еще происходят, и фактический системный вызов все еще блокирует.
Давайте подумаем о первой проблеме под рукой - копии. Как мы можем предотвратить копирование из пространства пользователя в пространство ядра? Ну, очевидно, нам нужна какая-то общая память. Хорошо, это можно сделать с помощьюсистемного вызова mmap , который может отобразить часть памяти, которая распределяется между пользователем и ядром.
Это заботится о копировании, но как насчет синхронизации? Даже если мы не копируем, нам нужен какой-то способ синхронизации доступа к данным между нами и ядром. В противном случае мы столкнемся с той же проблемой - потому что приложению потребуется снова выполнить системный вызов для выполнения блокировки.
Если мы посмотрим на проблему, когда пользователь и ядро являются двумя отдельными компонентами, взаимодействующими друг с другом - это, по сути, проблема производителя-потребителя. Пользователь создает запросы системного вызова, ядро принимает их. И как только это сделано, он сигнализирует пользователю, что он готов, и пользователь принимает их.
К счастью, существует давнее решение этой проблемы - кольцевые буферы. Кольцевой буфер обеспечивает эффективную синхронизацию между производителями и потребителями без какой-либо блокировки. И, как вы уже поняли, нам нужны два кольцевых буфера. Очередь отправки (SQ), в которой пользователь выступает в роли производителя и отправляет запросы на системный вызов, а ядро использует их. И очередь завершения (CQ), где ядро является производителем, отправляющим результаты завершения, и пользователь использует их.
С такой моделью мы полностью исключили любые копии памяти и блокировки. Все взаимодействие от пользователя к ядру может происходить очень эффективно. И это по сути основная идея, которая io_uring реализуется. Давайте кратко погрузимся в его внутренности и посмотрим, как это на самом деле реализовано.
Введение в io_uring
Чтобы отправить запрос в SQ, нам нужно создать запись в очереди отправки (SQE). Давайте предположим, что мы хотим прочитать файл. Скользя по множеству деталей, SQE будет в основном содержать:
- Опкод: код операции , который описывает системный вызов , чтобы быть сделано. Поскольку мы заинтересованы в чтении файла, мы будем использовать
readvсистемный вызов, который сопоставляется с кодом операцииIORING_OP_READV. - Флаги: это модификаторы, которые могут быть переданы с любым запросом. Мы доберемся до этого через мгновение.
- Fd: дескриптор файла, который мы хотим прочитать.
- Адрес: Для нашего
readvвызова он создает массив буферов (или векторов) для чтения данных. Следовательно, поле адреса содержит адрес этого массива. - Длина: длина нашего векторного массива.
- Пользовательские данные: идентификатор, который связывает наш запрос, когда он выходит из очереди завершения. Имейте в виду, что нет никакой гарантии, что результаты завершения будут появляться в том же порядке, что и SQE. Это победило бы всю цель наличия асинхронного API. Поэтому нам нужно что-то, чтобы идентифицировать запрос, который мы сделали. Это служит этой цели. Обычно это указатель на некоторую структуру, содержащую данные, которые имеют метаданные запроса.
На стороне завершения мы получаем событие очереди завершения (CQE) от CQ. Это очень простая структура, которая содержит:
- Результат: возвращаемое значение из
readvсистемного вызова. Если это успешно, у него будет число прочитанных байтов; в противном случае он будет иметь код ошибки. - Пользовательские данные: идентификатор, который мы передали в SQE.
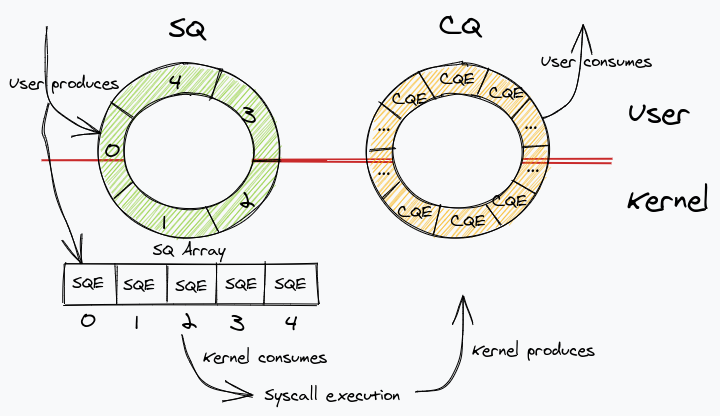
Здесь есть только одна важная деталь: SQ и CQ совместно используются пользователем и ядром. Но в то время как CQ на самом деле содержит CQE, для SQ это немного по-другому. По сути, это уровень косвенности, в котором значение индекса в массиве SQ фактически содержит индекс реального массива, содержащего элементы SQE. Это полезно для определенных приложений, которые имеют запросы на отправку внутри внутренних структур, и, следовательно, позволяет им отправлять несколько запросов за одну операцию, что существенно упрощает принятие io_uring API.
Это означает, что у нас на самом деле есть три вещи, отображенные в памяти: очередь отправки, очередь завершения и массив очереди отправки. Следующая диаграмма должна прояснить ситуацию.
Теперь давайте вернемся к flags полю, которое мы пропустили ранее. Как мы уже обсуждали, записи CQE могут полностью выходить из строя по сравнению с тем, что они были отправлены в очередь. Это поднимает интересную проблему. Что, если мы хотим выполнить последовательность операций ввода-вывода одну за другой? Например, копия файла. Мы хотели бы прочитать из файлового дескриптора и записать в другой. С текущим состоянием вещей мы даже не можем начать отправлять операцию записи, пока не увидим событие чтения в CQ. Вот где flags должен войти.
Мы можем установить IOSQE_IO_LINK в flags поле для достижения этой цели. Если это установлено, следующее SQE автоматически связывается с этим, и оно не запустится, пока текущее SQE не будет завершено. Это позволяет нам принудительно упорядочивать события ввода / вывода так, как мы хотим. Копирование файлов было только одним примером. Теоретически мы можем связать любой системный вызов один за другим, пока мы не нажмем SQE, где поле не установлено, и в этот момент цепь считается нарушенной.
Системные вызовы
С этим кратким обзором, как io_uring работает, давайте посмотрим на реальные системные вызовы, которые делают это. Их всего два.
int io_uring_setup(unsigned entries, struct io_uring_params *params);
entries обозначает число SQEs для этого кольца. params является структурой, которая содержит различные детали относительно CQ и SQ, которые должны использоваться приложением. Он возвращает дескриптор файла для этого io_uring экземпляра.
int io_uring_enter(unsigned int fd, unsigned int to_submit, unsigned int min_complete, unsigned int flags, sigset_t sig);
Этот вызов используется для отправки запросов в ядро. Давайте быстро пройдемся по важным из них:
fdявляется файловым дескриптором звонка, возвращенного из предыдущего вызова.to_submitсообщает ядру, сколько записей потреблять из кольца. Помните, что кольца находятся в общей памяти. Таким образом, мы можем отправить столько записей, сколько захотим, прежде чем просить ядро обработать их.min_completeуказывает, сколько записей следует ожидать до завершения вызова.
Проницательный читатель заметит, что наличие одного to_submit и min_complete того же вызова означает, что мы можем использовать его для выполнения либо только представления, либо только завершения, либо даже обоих! Это открывает API для использования различными интересными способами в зависимости от рабочей нагрузки приложения.
Режим опроса
Для приложений, чувствительных к задержке, или приложений с очень высоким IOPS, разрешение драйверу устройства прерывать ядро каждый раз, когда доступны данные для чтения, недостаточно эффективно. Если у нас будет много данных для чтения, высокая частота прерываний фактически замедлит производительность ядра для обработки событий. В этих ситуациях мы фактически возвращаемся к опросу драйвера устройства. Чтобы использовать опрос с помощью io_uring , мы можем установить IORING_SETUP_IOPOLL флаг в io_uring_setup вызове и продолжать опрашивать события с помощью IORING_ENTER_GETEVENTS набора в io_uring_enter вызове.
Но это все еще требует, чтобы «мы», пользователь, совершали звонки. Чтобы подняться еще выше, io_uring также имеется функция, называемая «опрос на стороне ядра», при которой, если мы установим IORING_SETUP_SQPOLL флаг io_uring_params , ядро автоматически опрашивает SQ, чтобы проверить наличие новых записей и использовать их. По сути, это означает, что мы можем продолжать делать все необходимые операции ввода-вывода, не выполняя ни одного . система . звоните . Это меняет все.
Но вся эта гибкость и грубая сила обходятся ценой. Использование этого API напрямую не является тривиальным и подверженным ошибкам. Поскольку наши структуры данных совместно используются пользователем и ядром, нам необходимо настроить барьеры памяти (магические заклинания компилятора для обеспечения упорядочения операций с памятью) и другие мелочи, чтобы все было сделано правильно.
К счастью, создатель Jens Axboe io_uring создал библиотеку-обертку, призванную liburing помочь упростить все это. Приблизительно liburing мы должны выполнить этот набор шагов:
-
io_uring_queue_(init|exit)установить и снести кольцо. -
io_uring_get_sqeчтобы получить SQE. -
io_uring_prep_(readv|writev|other)чтобы отметить, какой системный вызов использовать. -
io_uring_sqe_set_dataпометить поле данных пользователя. -
io_uring_(wait|peek)_cqeлибо ждать CQE, либо искать его, не дожидаясь. -
io_uring_cqe_get_dataчтобы вернуть поле пользовательских данных. -
io_uring_cqe_seenотметить CQE как выполненное.
Упаковка io_uring в Go
Это было много теории, чтобы переварить. Есть еще кое-что, что я намеренно пропустил ради краткости. Теперь вернемся к написанию некоторого кода на Go и рассмотрим его. Для простоты и безопасности мы будем использовать liburing библиотеку, а это значит, что нам нужно будет использовать CGo. Это нормально, потому что это всего лишь игрушка, и правильным способом будет иметь встроенную поддержку во время выполнения Go. В результате нам, к сожалению, придется использовать обратные вызовы. В нативном Go выполняющаяся программа будет помещена в спящий режим во время выполнения, а затем проснется, когда данные будут доступны в очереди завершения.
Давайте назовем наш пакет frodo (и именно так я выбил одну из двух самых сложных проблем в информатике). У нас будет очень простой API для чтения и записи файлов. И еще две функции для настройки и очистки кольца, когда закончите.
Нашей основной рабочей лошадкой будет единственная программа, которая принимает запросы на отправку и отправляет их в SQ. И из C мы сделаем обратный вызов Go с записью CQE. Мы будем использовать fd файлы, чтобы узнать, какой обратный вызов выполнить после получения наших данных. Однако нам также необходимо решить, когда фактически отправлять очередь в ядро. Мы поддерживаем порог очереди, и если мы превышаем порог ожидающих запросов, мы отправляем. Кроме того, мы предоставляем пользователю другую функцию, которая позволяет ему самостоятельно отправлять данные, чтобы они могли лучше контролировать поведение приложения.
Обратите внимание, что это опять-таки неэффективный способ ведения дел. Поскольку CQ и SQ полностью разделены, они вообще не нуждаются в какой-либо блокировке, и поэтому отправка и завершение могут происходить свободно из разных потоков. В идеале, мы просто помещаем запись в SQ и проводим отдельную процедуру прослушивания для ожидания завершения, и всякий раз, когда мы видим запись, мы делаем обратный вызов и возвращаемся к ожиданию. Помните, что мы можем использовать io_uring_enter только для завершения? Вот один из таких примеров! Это все еще делает один системный вызов для каждой записи CQE, и мы можем даже оптимизировать его, указав количество ожидающих записей CQE.
Возвращаясь к нашей упрощенной модели, вот псевдокод того, как это выглядит:
// ReadFile reads a file from the given path and returns the result as a byte slice
// in the passed callback function.
func ReadFile(path string, cb func(buf []byte)) error {
f, err := os.Open(path)
// handle error
fi, err := f.Stat()
// handle error
submitChan <- &request{
code: opCodeRead, // a constant to identify which syscall we are going to make
f: f, // the file descriptor
size: fi.Size(), // size of the file
readCb: cb, // the callback to call when the read is done
}
return nil
}
// WriteFile writes data to a file at the given path. After the file is written,
// it then calls the callback with the number of bytes written.
func WriteFile(path string, data []byte, perm os.FileMode, cb func(written int)) error {
f, err := os.OpenFile(path, os.O_WRONLY|os.O_CREATE|os.O_TRUNC, perm)
// handle error
submitChan <- &request{
code: opCodeWrite, // same as above. This is for the writev syscall
buf: data, // the byte slice of data to be written
f: f, // the file descriptor
writeCb: cb, // the callback to call when the write is done
}
return nil
}
submitChan отправляет запросы на нашу основную рабочую лошадку, которая отвечает за их отправку. Вот псевдокод для этого:
queueSize := 0
for {
select {
case sqe := <-submitChan:
switch sqe.code {
case opCodeRead:
// We store the fd in our cbMap to be called later from the callback from C.
cbMap[sqe.f.Fd()] = cbInfo{
readCb: sqe.readCb,
close: sqe.f.Close,
}
C.push_read_request(C.int(sqe.f.Fd()), C.long(sqe.size))
case opCodeWrite:
cbMap[sqe.f.Fd()] = cbInfo{
writeCb: sqe.writeCb,
close: sqe.f.Close,
}
C.push_write_request(C.int(sqe.f.Fd()), ptr, C.long(len(sqe.buf)))
}
queueSize++
if queueSize > queueThreshold { // if queue_size > threshold, then pop all.
submitAndPop(queueSize)
queueSize = 0
}
case <-pollChan:
if queueSize > 0 {
submitAndPop(queueSize)
queueSize = 0
}
case <-quitChan:
// possibly drain channel.
// pop_request till everything is done.
return
}
}
cbMap сопоставляет дескриптор файла с действительной функцией обратного вызова, которая будет вызвана. Это используется, когда код CGo вызывает код Go, сигнализируя о завершении события. submitAndPop звонки io_uring_submit_and_wait с queueSize . А потом выскакивают записи из CQ.
Давайте посмотрим на то, что C.push_read_request и C.push_write_request делает. По сути, все, что они делают - это отправляют запрос на чтение / запись в SQ.
Они похожи:
int push_read_request(int file_fd, off_t file_sz) {
// Create a file_info struct
struct file_info *fi;
// Populate the struct with the vectors and some metadata
// like the file size, fd and the opcode IORING_OP_READV.
// Get an SQE.
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
// Mark the operation to be readv.
io_uring_prep_readv(sqe, file_fd, fi->iovecs, total_blocks, 0);
// Set the user data section.
io_uring_sqe_set_data(sqe, fi);
return 0;
}
int push_write_request(int file_fd, void *data, off_t file_sz) {
// Create a file_info struct
struct file_info *fi;
// Populate the struct with the vectors and some metadata
// like the file size, fd and the opcode IORING_OP_WRITEV.
// Get an SQE.
struct io_uring_sqe *sqe = io_uring_get_sqe(&ring);
// Mark the operation to be writev.
io_uring_prep_writev(sqe, file_fd, fi->iovecs, 1, 0);
// Set the user data section.
io_uring_sqe_set_data(sqe, fi);
return 0;
}
И когда submitAndPop пытается извлечь записи из CQ, это выполняется:
int pop_request() {
struct io_uring_cqe *cqe;
// Get an element from CQ without waiting.
int ret = io_uring_peek_cqe(&ring, &cqe);
// some error handling
// Get the user data set in the set_data call.
struct file_info *fi = io_uring_cqe_get_data(cqe);
if (fi->opcode == IORING_OP_READV) {
// Calculate the number of blocks read.
// Call read_callback to Go.
read_callback(fi->iovecs, total_blocks, fi->file_fd);
} else if (fi->opcode == IORING_OP_WRITEV) {
// Call write_callback to Go.
write_callback(cqe->res, fi->file_fd);
}
// Mark the queue item as seen.
io_uring_cqe_seen(&ring, cqe);
return 0;
}
read_callback И write_callback просто получить запись из cbMap с переданными fd и вызвать необходимые функции обратного вызова функции , которые первоначально сделал ReadFile / WriteFile вызов.
//export read_callback
func read_callback(iovecs *C.struct_iovec, length C.int, fd C.int) {
var buf bytes.Buffer
// Populate the buffer with the data passed.
cbMut.Lock()
cbMap[uintptr(fd)].close()
cbMap[uintptr(fd)].readCb(buf.Bytes())
cbMut.Unlock()
}
//export write_callback
func write_callback(written C.int, fd C.int) {
cbMut.Lock()
cbMap[uintptr(fd)].close()
cbMap[uintptr(fd)].writeCb(int(written))
cbMut.Unlock()
}
И это в основном все! Пример использования библиотеки будет выглядеть так:
err := frodo.ReadFile("shire.html", func(buf []byte) {
// handle buf
})
if err != nil {
// handle err
}
Не стесняйтесь проверить источник, чтобы проникнуть в мелочи реализации.
Производительность
Ни одно сообщение в блоге не является полным без некоторых показателей производительности. Однако для правильного сравнения производительности модулей ввода-вывода, возможно, потребуется еще один пост в блоге. Для полноты картины я просто опубликую результаты своего короткого и ненаучного теста на своем ноутбуке. Не читайте слишком много, потому что любые тесты сильно зависят от рабочей нагрузки, параметров очереди, аппаратного обеспечения, времени суток и цвета вашей рубашки.
Мы будем использовать fio - отличный инструмент, написанный самим Йенсом, для сравнения нескольких механизмов ввода / вывода с различными рабочими нагрузками, поддерживающими оба io_uring и libaio . Слишком много ручек для изменения. Но мы проведем очень простой эксперимент, используя рабочую нагрузку случайного чтения / записи с соотношением 75/25, файл размером 1 ГБ и различные размеры блоков: 16 КБ, 32 КБ и 1 МБ. А затем мы повторим весь эксперимент с размерами очередей 8, 16 и 32.
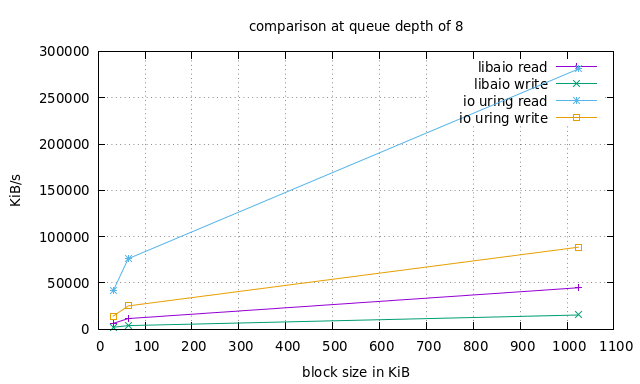
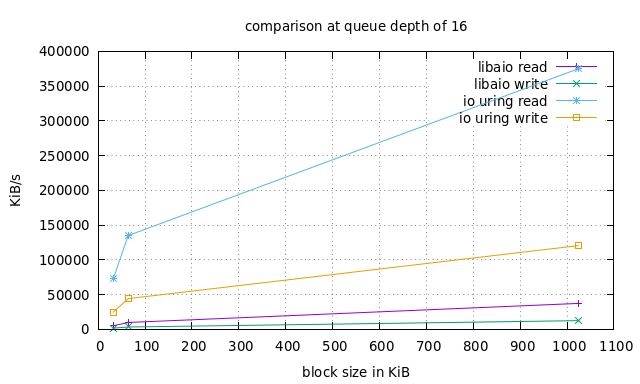
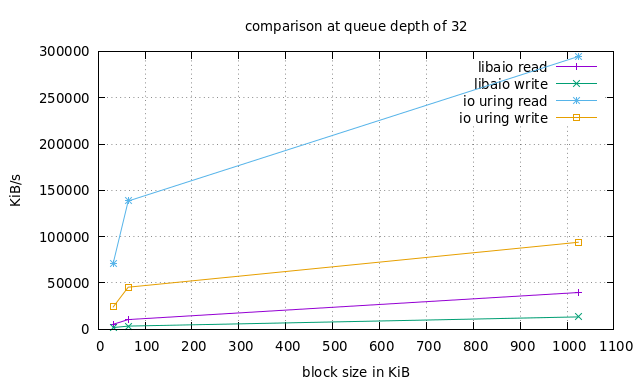
Обратите внимание, что это io_uring в основном режиме без опроса, и в этом случае результаты могут быть еще выше.
Вывод
Это был довольно большой пост, и спасибо, что прочитали до сих пор!
io_uring все еще находится на начальной стадии, но быстро набирает обороты. Многие громкие имена (libuv, RocksDB) уже поддерживают это. Существует даже патч для nginx, который добавляет поддержку io_uring. Будем надеяться, что поддержка Go будет добавлена в ближайшее время.
Каждая новая версия ядра получает новые функции API, и все больше и больше системных вызовов начинают поддерживаться. Это захватывающая новая граница для производительности Linux!
Ниже приведены некоторые ресурсы, которые я использовал для подготовки к этому посту. Пожалуйста, проверьте их, если вы хотите узнать больше.
И, наконец, я хотел бы поблагодарить моих коллег Ибрагима и Клаудио за корректуру и исправление моего ужасного кода Си.
Ресурсы:
- https://kernel.dk/io_uring.pdf
- https://kernel.dk/io_uring-whatsnew.pdf
- https://www.youtube.com/watch?v=-5T4Cjw46ys
- https://lwn.net/Articles/776703/
- https://github.com/axboe/liburing
Автор Агнива Де Саркер - @agnivade на community.mattermost.com и @agnivade на GitHub